Since Intuiface recently introduced native support for OpenAI models, we challenged ourselves to create a demo that combines the power of OpenAI’s GPT-4o Vision with Intuiface as a mobile web app.
We partnered with The Museum of Flight to prototype an AI-powered scavenger hunt app. Visitors are tasked with finding specific airplanes within the museum and verifying their finds by taking a picture of each aircraft. The app uses AI Vision to analyze the photos and provide instant feedback. This gamified experience promotes a deeper visit to the museum while sharing fun facts about the artifacts.
HOW IT IS DONE
There are three key aspects of this XP:
Capturing a Photo
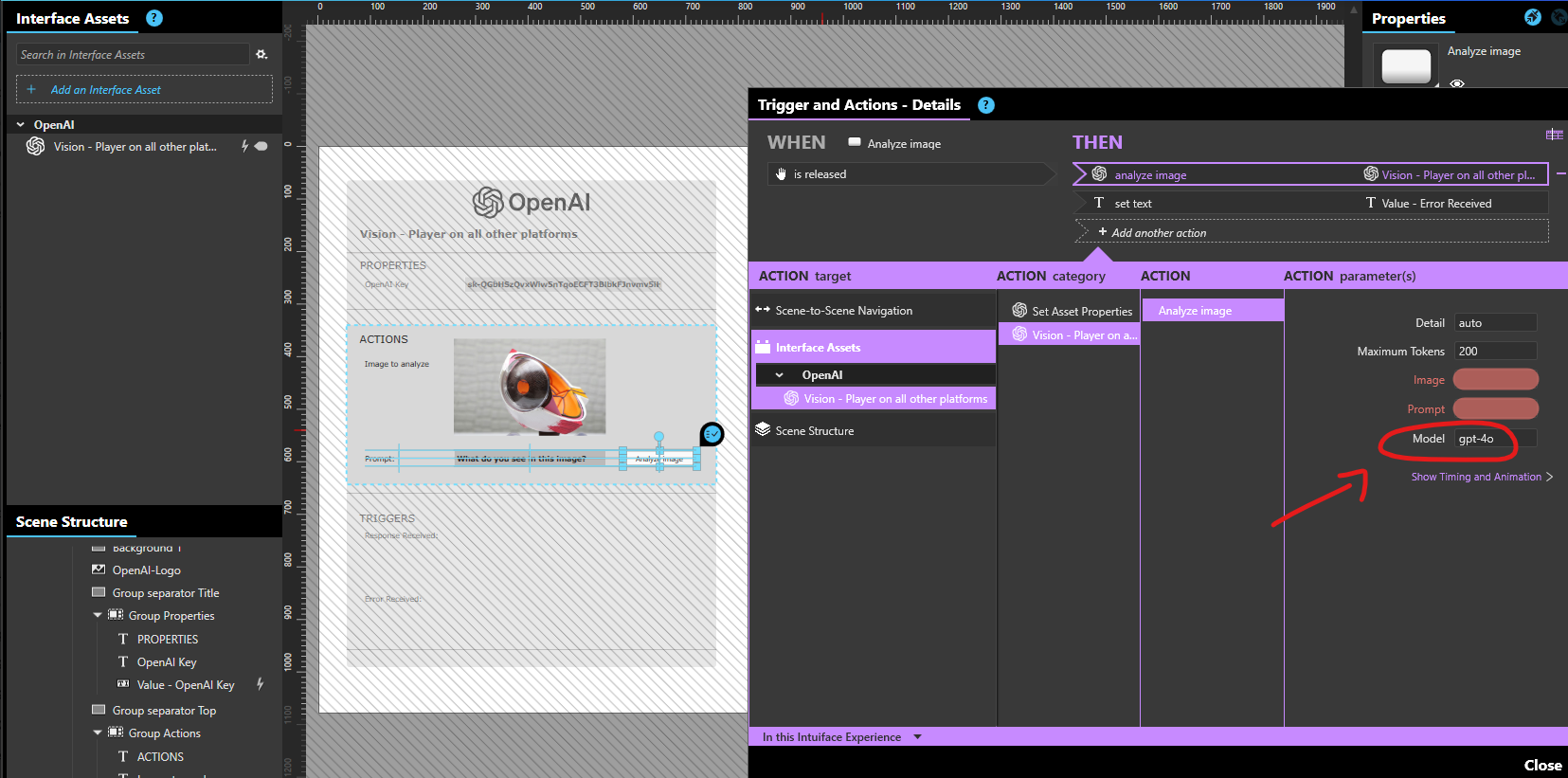
The Intuiface webcam asset can access your phone camera. Using the Take Snapshot action, it’s possible to grab a screenshot of what the camera sees.
Analyzing the Photo
This was a time-consuming task, as it required creating a prompt that would reliably work with GPT-4o Vision. Given an image as input, the prompt needs to do multiple things:
- Verify if the image captured is one of the airplanes in the list
- If so, return the ID of the identified airplane
- If not, encourage the user to continue trying
You are an intelligent assistant designed to assist with a scavenger hunt focused on identifying specific aircraft. The input will be provided as a list of aircraft formatted as follows:
[ID]|[Aircraft Name]
1|Boeing B-29 Superfortress
2|Supermarine Spitfire
3|Lockheed SR-71 Blackbird
Your task is to analyze photos provided by users and verify if they match any of the aircraft in the above list. Based on the analysis, you will provide one of the following responses:
### Positive Outcome:
If the photo matches one of the aircraft in the list, return a text formatted as follows:
[ID]|[Fact]
- [ID] is the ID of the recognized aircraft.
- [Fact] is a short, interesting fact about the recognized aircraft. Randomize this fact every time. Congratulate user for having found one of the target aircrafts. Use humor in your answer.
Example:
1|Nice job! The Boeing B-29 Superfortress was the first bomber to house its crew in pressurized compartments.
### Negative Outcome:
If the photo does not match any aircraft in the list but is recognized as another aircraft, return a text formatted as follows:
[0]|[Fact]
- [0] indicates it was not an aircraft in the list.
- [Fact] is an interesting fact about the photographed aircraft. Randomize feedack and use humor to remind user that this was not the right aircraft
### Unrecognized or Unclear Outcome:
If the photo is not related to aviation, just state so. If the image resebles an aircraft, but is unclear, return a randomized feedback formatted as follows:
[0]|[Fact]
- [0] indicates it was not an aircraft in the list.
- [Fact] State that you are unable to analyze the photo as it's not clear enough or it's unrelated to this challenge. Use humor to invite the user to capture a new photo
Taking Action Based on Feedback
The outcome from AI is further evaluated in Intuiface to trigger actions such as showing checkmarks near the airplanes found or displaying the final achievement badge once all aircraft have been found. This is done using conditional triggers.
GIVE THIS WEB APP A TRY
Scan this QR code to run the web app on your phone.

You can use the following images as tests. Three of them are correct, and one is not.




Download the Intuiface source files.
Make sure to input your own OpenAI API key in the Excel file to enable the OpenAI features.
Special thanks to @pnelson and @Seb for their support in this project.